Event-driven PII scanning in BigQuery using Stackdriver, Cloud Functions & DLP
The <TL;DR>
I shamelessly copied a great solution from someone else, tweaked it slightly and made it event-driven. The solution wires together a conga line of Stackdriver, Cloud Functions, Pub/Sub and Cloud Data Loss Prevention (DLP) to perform PII scanning of any new table that is created in BigQuery. How? Well, I’m glad you asked. I created a filter in Stackdriver to monitor for new table events in BigQuery and sent the resulting log entries to a Pub/Sub topic. I then hung a Cloud Function (Python3) off the Pub/Sub topic that parses the BigQuery table event, does some magic and finally calls the DLP API to perform a PII scan on the newly created table. Finally, DLP writes the results of its scan back to BigQuery as a table. Nifty, eh?
Code can be found in GitHub here.
An original thought..from someone else
I recently read this really good article about automatically doing PII detection at scale in BigQuery using DLP. It uses scheduling, which a fine solution indeed. Having a proactive approach to detecting PII in your datasets will certainly earn you some valuable brownie points with your security and privacy teams. However, I thought it might be useful (and fun) to take it a step further by making it completely event-driven instead of schedule based. Unfortunately, BigQuery doesn’t have any native webhooks for events, nor does it emit its event to Pub/Sub. Instead, the workaround is to tap into BigQuery’s events though its logs in Stackdriver. Somewhat convoluted I agree, but as my good friends Balkan and Mark show, it works just fine. High five! I just needed to take it a bit further than what they’d both done, and capture all new table created in BigQuery, but the idea was still the same.
p.s. BigQuery PMs, if you’re reading this, we need a better way to get notified of events :)
Ok cobblers, let’s get cobbling
I’m going to assume that most people reading my nonsense know their way around GCP pretty well, and are relatively comfortable with all the tools I used to cobble this solution together. The first thing we need to do is create the Pub/Sub topic to received the table events:
$ gcloud pubsub topics create bigquery_new_tablesWow, that was hard. Next up, is the Stackdriver log filter and export sink. We need to create an advanced filter in Stackdriver to capture new table events in BigQuery. There’s a few ways that a table can be created in BigQuery (load, query, copy, insert etc.). See the official docs here for more details on that. Now, I’ve probably missed something (please holla at me if I did), but here’s the log filter that I came up with to capture any new table creation event in BigQuery:
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.query.destinationTable:* OR
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.tableCopy.destinationTable:* OR
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable:* OR
protoPayload.methodName=tableservice.insert
AND severity!=ERROR
AND NOT protoPayload.authenticationInfo.principalEmail:@dlp-api.iam.gserviceaccount.comThe first few lines should be self-explanatory. The only thing to really call out here is the last line (LN 6). Remember, the solution will trigger DLP to write the results of its PII scan back to BigQuery as a table. Ergo, we’ll get an event triggered for that too, and we obviously don’t want to process that one because we’ll end up in a beautifully expensive endless loop. So, the hack I came up with was to filter out any tables that are created by the service account that DLP uses to talk to BigQuery, which is identifiable by the xxx@dlp-api.iam.gserviceaccount.com email in the log entry. Again, there’s probably a better way to do this, but I was too lazy (and incompetant) to investigate it further. With the filter written, we can create the actual Stackdriver sink and point it to the Pub/Sub topic:
$ gcloud logging sinks create \
all_new_bigquery_tables pubsub.googleapis.com/projects/<project-id>/topics/bigquery_new_tables \
--log-filter="<ugly_filter_above>"Let’s have a look at that newly created Stackdriver sink shall we:
$ gcloud logging sinks list
NAME DESTINATION FILTER
all_new_bigquery_tables pubsub.googleapis.com/bigquery_new_tables protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.query.destinationTable:* OR
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.tableCopy.destinationTable:* OR
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable:* OR
protoPayload.methodName=tableservice.insert
AND severity!=ERROR
AND NOT protoPayload.authenticationInfo.principalEmail:@dlp-api.iam.gserviceaccount.comRad!
A Java dev writing some very dodgy Python code
There’s a few ways to hang off the Pub/Sub topic and handle the new table events. For example, you could use Cloud Build or Cloud Run. I’m a big fan of both those tools, but they both felt a little bit heavyweight for what I needed, which was essentially to parse the new table event in BigQuery, scrape some details from the payload and invoke the DLP API. In the end, I settled on writing a simple-ish CLoud Function using Python.
My Python is shocking, so I apologise in advance to all the Pythonistas reading this. The reason I picked Python over Node or Java (now in private alpha btw) was because the majority of the stuff I needed to copy and paste from documentation and blogs was also written in Python. Remember the wise words of Kelsey Hightower y’all: “Good programmers copy, GREAT programmers paste!". Missing my beloved JVM, I got to work piecing together the Cloud Function from various sources. Along the way, I encountered some interesting edge cases:
- When a view is created in BigQuery, the API call is the same as for a new table. I needed to handle this. Yikes!
- When a query is run in BigQuery, if destination table is not set, it will write the results to a temporary table and a hidden dataset that Google manage on your behalf. But, in the logs, the event looks identical to a query which has been configured to save its results to a destination table. The only difference is the table and dataset name, which are both a unique hash/GUID. The workaround for this is to list all datasets and check if the destination dataset is a match. If not, the code ignores it and assumes that it’s a user running a normal query. Some might argue that the temp tables should be scanned by DLP as well, but I’d say that it’s overkill.
Before we deploy the code for the Cloud Function, we first need a requirements.txt that brings in the BigQuery and DLP client libraries:
# Function dependencies, for example:
# package>=version
google-cloud-bigquery
google-cloud-dlpThe Cloud Function itself was straightforward enough. Some notable snippets are coming up. Try not to snigger. The first one is a safety net just in case the Stackdriver filter fails (e.g. someone updates and breaks it) and tables created by the DLP service flow through to the Cloud Function. We don’t want this happening.
...
# This shouldn't happen as it will be filtered out by Stackdriver but let's check anyway
caller_email = obj['protoPayload']['authenticationInfo']['principalEmail']
if caller_email.endswith('@dlp-api.iam.gserviceaccount.com'):
logger.error('This is a DLP table creation event. This should not have come through!')
else:
...The next snippet shows the handling of the first edge case of a view creation coming through disguised as a new table. You sneaky bugger BigQuery!
...
if 'tableInsertRequest' in service_data:
resource = service_data['tableInsertRequest']['resource']
if not resource['view']: # ignore views
logger.debug("Table insert event")
table_info = extract_table_and_dataset(resource, 'tableName')
...Finally, this is the code for dealing with the 2nd edge case. That’s the one where a query is run and the results are written to a temp table and hidden dataset behind the scenes, remember? Of course you do.
...
elif 'query' in job_configuration:
logger.debug("Query job event")
table_info = extract_table_and_dataset(job_configuration['query'], 'destinationTable')
if not is_materialized_query(bigquery.Client(), table_info): # ignore unmaterialized queries
logger.info("Ignoring query creation event because it was not materialized by user")
table_info = None
...
def is_materialized_query(bq_client, table_info):
"""Works out if the destination table is a hidden dataset/table i.e. a normal query
Args:
bq_client: BigQuery client
table_info: encapsulates the table id and dataset id
"""
datasets = list(bq_client.list_datasets())
project = bq_client.project
if datasets:
for dataset in datasets:
if table_info.dataset_id.lower() == dataset.dataset_id.lower():
return True
return False
...Pulling it all together
With just enough Python knowledge to be dangerous, it’s time to pull it all together and deploy the Cloud Function. So, let’s do that now.
import base64
import json
import logging
import collections
import time
from google.cloud import bigquery
from google.cloud import dlp
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def biqquery_new_table_event_from_pubsub(event, context):
"""Triggered from a message on a Cloud Pub/Sub topic.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
pubsub_message = base64.b64decode(event['data']).decode('utf-8')
obj = json.loads(pubsub_message)
logger.info("Received the following payload: '{}'".format(obj))
# This shouldn't happen as it will be filtered out by Stackdriver but let's check anyway
caller_email = obj['protoPayload']['authenticationInfo']['principalEmail']
if caller_email.endswith('@dlp-api.iam.gserviceaccount.com'):
logger.error('This is a DLP table creation event. This should not have come through!')
else:
service_data = obj['protoPayload']['serviceData']
table_info = None
# Work out the event
if 'tableInsertRequest' in service_data:
resource = service_data['tableInsertRequest']['resource']
if not resource['view']: # ignore views
logger.debug("Table insert event")
table_info = extract_table_and_dataset(resource, 'tableName')
elif 'jobCompletedEvent' in service_data:
job_configuration = service_data['jobCompletedEvent']['job']['jobConfiguration']
if 'load' in job_configuration:
logger.debug("Load job event")
table_info = extract_table_and_dataset(job_configuration['load'], 'destinationTable')
elif 'query' in job_configuration:
logger.debug("Query job event")
table_info = extract_table_and_dataset(job_configuration['query'], 'destinationTable')
if not is_materialized_query(bigquery.Client(), table_info): # ignore unmaterialized queries
logger.info("Ignoring query creation event because it was not materialized by user")
table_info = None
elif 'tableCopy' in job_configuration:
logger.debug("Table copy event")
table_info = extract_table_and_dataset(job_configuration['tableCopy'], 'destinationTable')
else:
logger.error("I've no idea what this event is. Send help, now!")
else:
logger.error("I've no idea what this event is. Send help, now!")
if table_info:
logger.info("A table with id: '{}' was created in dataset: '{}'".format(table_info.table_id, table_info.dataset_id))
dlp_all_the_things(table_info)
def is_materialized_query(bq_client, table_info):
"""Works out if the destination table is a hidden dataset/table i.e. a normal query
Args:
bq_client: BigQuery client
table_info: encapsulates the table id and dataset id
"""
datasets = list(bq_client.list_datasets())
project = bq_client.project
if datasets:
for dataset in datasets:
if table_info.dataset_id.lower() == dataset.dataset_id.lower():
return True
return False
def extract_table_and_dataset(payload, key):
TableInfo = collections.namedtuple('TableInfo', ['project_id', 'dataset_id', 'table_id'])
table_info = TableInfo(payload[key]['projectId'], payload[key]['datasetId'], payload[key]['tableId'])
return table_info
def dlp_all_the_things(table_info):
project = table_info.project_id
dataset = table_info.dataset_id
table = table_info.table_id
dlp_client = dlp.DlpServiceClient()
logger.info("DLP'ing all the things on '{}.{}.{}'".format(project, dataset, table))
inspect_config = {
'info_types': [],
'min_likelihood': 'POSSIBLE'
}
storage_config = {
'big_query_options': {
'table_reference': {
'project_id': project,
'dataset_id': dataset,
'table_id': table,
}
}
}
parent = dlp_client.project_path(project)
actions = [{
'save_findings': {
'output_config': {
'table': {
'project_id': project,
'dataset_id': dataset,
'table_id': '{}_dlp_scan_results_{}'.format(table, int(round(time.time() * 1000))),
}
}
}
}]
inspect_job = {
'inspect_config': inspect_config,
'storage_config': storage_config,
'actions': actions,
}
dlp_client.create_dlp_job(parent, inspect_job=inspect_job)The Cloud Function simply listens for the events from Pub/Sub (triggered by the Stackdriver logs), parses it and then calls the DLP service to scan the newly created table for any PII info. Using some more gcloud magic, deploying the Cloud Function was a breeze:
$ gcloud functions deploy biqquery_new_table_event_from_pubsub \
--runtime python37 -\
-trigger-topic bigquery_new_tablesShaking out the conga line
With all the plumbing in place, the final thing to do is to test if it actually works. As I’ve mentioned a few times already in this post, there’s a few ways to create a table in BigQuery (again, if I’m missing something please let me know), but as a simple test we can run the following query and materialise the results to a new table to see if it triggers the pipeline (spoiler: I’m writing this blog after the fact, so of course it does):
$ bq query --destination_table=grey-sort-challenge:new_tables.from_a_query \
"SELECT 'Graham Polley' AS a, 'foo' AS b, 'foo@bar.com' AS c, 40 AS d, '4556-9987-3334-3334' as e"
Waiting on bqjob_r6498d82b08e6e9cf_0000016b7449cbb9_1 ... (4s) Current status: DONE
+---------------+-----+-------------+----+---------------------+
| a | b | c | d | e |
+---------------+-----+-------------+----+---------------------+
| Graham Polley | foo | foo@bar.com | 40 | 4556-9987-3334-3334 |
+---------------+-----+-------------+----+---------------------+Let’s now check the Cloud Function logs to see if it fired:
$ gcloud logging read "resource.type=cloud_function"
---
textPayload: "Function execution took 955 ms, finished with status: 'ok'"
timestamp: '2019-06-20T09:58:36.739743030Z'
---
textPayload: DLP'ing all the things on 'grey-sort-challenge.new_tables.from_a_query'
timestamp: '2019-06-20T09:58:36.045Z'
---
textPayload: "A table with id: 'from_a_query' was created in dataset: 'new_tables'"
timestamp: '2019-06-20T09:58:36.037Z'
---
textPayload: Function execution started
timestamp: '2019-06-20T09:58:35.786271011Z'Yeehaw y’all! The Cloud Function triggered when the query was run in BigQuery and the results were materialized to a table (new_tables.from_a_query). The last thing we need to check is if DLP did its thing, and scanned the newly created table in BigQuery for any PII. Cloud DLP doesn’t appear to have gcloud integration yet (boo!), so to check it let’s jump into the GCP console:
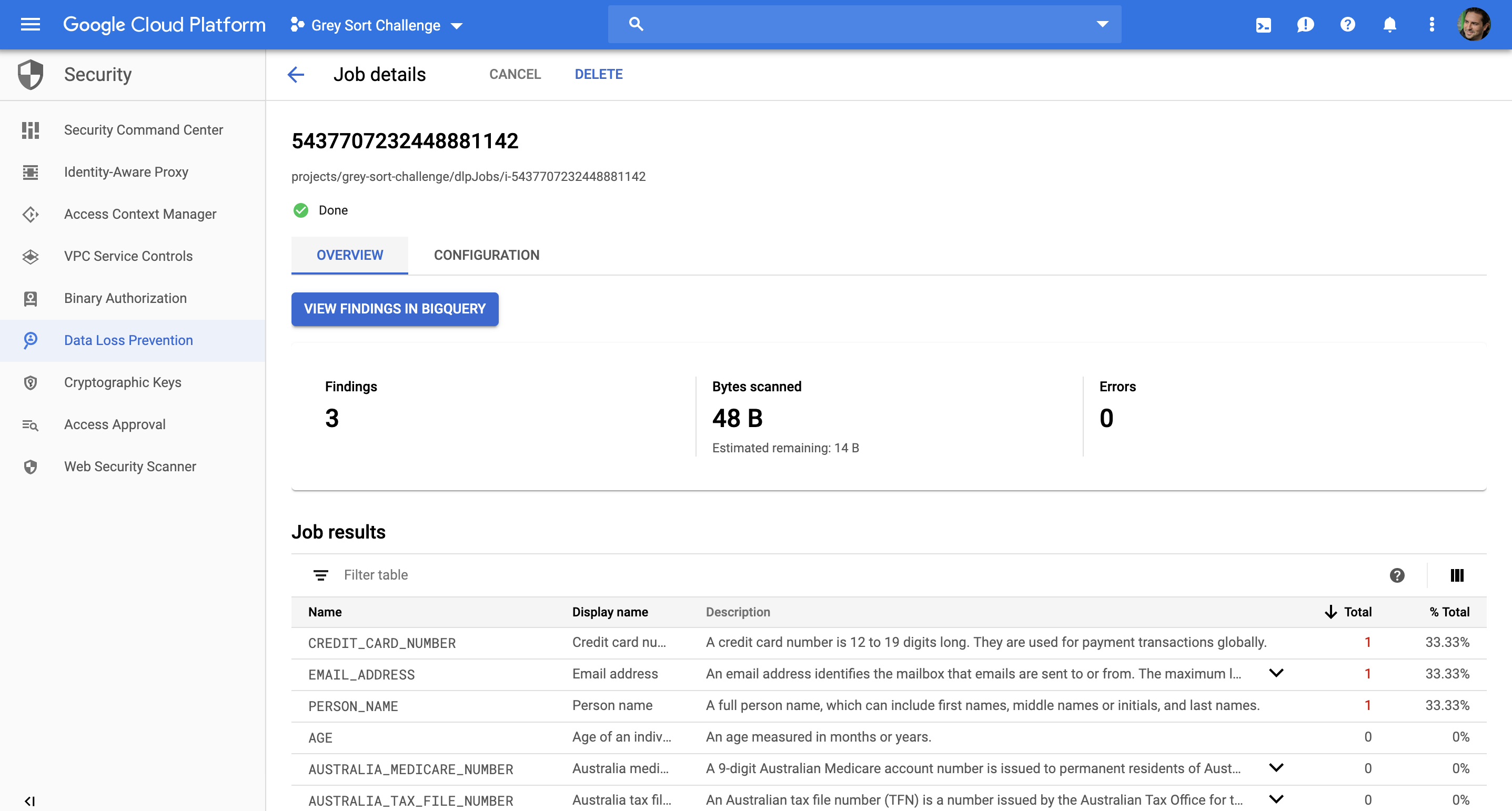
Sweet. DLP ran over the new table in BigQuery, and surprise, surprise, it found some PII. To be specific it found one occurance of each a CREDIT_CARD_NUMBER, EMAIL_ADDRESS, and PERSON_NAME. Note: I just used the default settings for DLP, but you can of course custom tune it to suit your needs i.e. templates, custom infoTypes etc.
Stay with me here folks. We’re almost there! Finally, let’s take a peek at BigQuery and the table where DLP wrote its results to:
$ bq query --format=prettyjson \
"select * from new_tables.from_a_query_dlp_scan_results_1561024716046"
Waiting on bqjob_r4ea14ffed9347ec0_0000016b77418116_1 ... (0s) Current status: DONE
[
{
"create_time_nanos": "414000000",
"create_time_seconds": "1561024821",
"info_type_name": "CREDIT_CARD_NUMBER",
"likelihood": "LIKELY",
"location_byte_range_end": "19",
"resource_name": "projects/grey-sort-challenge/dlpJobs/i-5437707232448881142"
},
{
"create_time_nanos": "425000000",
"create_time_seconds": "1561024821",
"info_type_name": "EMAIL_ADDRESS",
"likelihood": "LIKELY",
"location_byte_range_end": "11",
"resource_name": "projects/grey-sort-challenge/dlpJobs/i-5437707232448881142"
},
{
"create_time_nanos": "602000000",
"create_time_seconds": "1561024821",
"info_type_name": "PERSON_NAME",
"likelihood": "LIKELY",
"location_byte_range_end": "13",
"resource_name": "projects/grey-sort-challenge/dlpJobs/i-5437707232448881142"
}
]And there you have it peeps. A cobbled together solution using some nifty tools on the GCP stack for an event-driven DLP pipeline that scans for PII in BigQuery. Aww snap!
Wrapping up
I had fun building this little pipeline. I think it highlights how you need to get creative sometimes to solve problems, and that the trick to building solutions on the cloud is to know how to wire up the services/tools and how they work together. A few things:
- The pipeline also fires when appending new rows to a table and DLP will scan the entire table. I didn’t get time to look into just scanning the appended rows or a newly created partition in a partitioned table for example. Being a father of two little ankle-biters makes finding time very hard indeed.
- If you’re working with large datasets, running a DLP scan on every single new table might be cost prohibitive. Be smart, and think about what works best for you. Feel free to take this code and adapt.
- Cloud DLP is a global service and cannot be region locked yet. When you run a PII scan on a table in BigQuery, I’m not entirely sure how this is working under the hood. I couldnt’ find any documentation on it. My best guess is that it’s perhaps spinning up a Dataflow pipeline in a tenanted project, and checking your data with some fancy regex. Or, maybe it’s just running some SQL (again with some fancy regex) directly in BigQuery. I don’t actually know! But, the point here is that you need to be aware that it’s a global service, and as such, it’s not transparent to you where your data is actually being handled and processed.
Finally, the inspiration for this came from other people like Doug, Mark and Balkan. Having people like this who continue to share what they’ve built with the community is so helpful and impactful. Kudos.